CNN简史 A Brief History of Convolutional Neural Network
今天我们来回顾一下CNN发展的历史,为什么要做这个总结呢,除了本身对科学史感一点兴趣外,追踪整个CNN发展的思路也是非常有趣的事。我们知道科学的发展往往不是一往无前的,不是按照教科书上编排那样诞生的。举一个可能和大家直觉相悖的例子,打火机早于火柴被发明,而ReLU比tanh更早被应用在神经网络中。
本文需要读者对CNN有一点点了解,包括基础的卷积池化操作是怎么完成的等等。
很久很久以前
我们知道,神经网络这一概念最早是生物界提出的,而人工智能界的神经网络很大程度上是在模拟人类的神经元。虽然业界对我们是否需要继续仿生这条路,还是开辟一条不同于生物神经网络的路还有不少的争议,但是读完很多论文我发现现代人工神经网络受生物研究的影响可能比我们想象中要更大。
影响到CNN起源的相关研究是有关视觉皮层的,其中较著名的是Hubel 和Wiesel1968年做出的工作。在这项工作前,人们已经对这个领域有一些了解。我将他们罗列出来。
- 首先我们人类的大脑有$10^11$的神经元,每个神经元上有1000个轴突,也就是说有$10^14$个神经连接。
- 另外每只人类的眼睛有$10^8$个视觉接收器(比如视锥,视杆等等),但是我们只有$10^6$的视觉神经。因此,我们可以知道每一个视觉神经都接收来自许多视觉接受细胞的输入。
- 另外一个已经被实验表明的点是,我们视觉神经不是简单的告诉大脑光线被检测到,而是说光线和黑暗之间的对比,也就是形状被感受到了。
- 最后人们发现我们的每个单个神经元并不会对整个图像做出回应,而是只对其负责的receptive filed响应,这里有人翻译为感受野,也有称作接受域的。
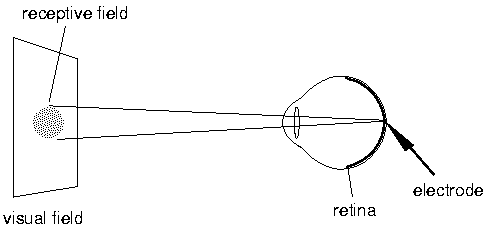
在这些事实的基础上,Hubel和Wiesel干了一件事,他们将猫麻醉后,把电极插到其视觉神经上连接示波器,并给它们看不同的图像,观察脑电波的反应。
当然,这个实验也引起了许多爱猫人士的抗议2333,我们可以看一个视频来看下他们是怎么做的。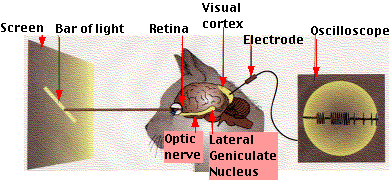
由这个实验,他们得到了一些新的有趣的现象:
- 外侧膝状核LGN会响应一个微小的光点,但是对漫反射没什么回应。
- 视觉皮层从LGN接受信息时,它们不再响应光圈,但是对亮暗的线条有回应。
- 视觉皮层中有一类简单的皮质细胞,只会在以特定角度刺激特定区域时才会响应。 对于某个简单细胞的无效响应区域会是另一个细胞的有效响应
- 其他细胞(复杂皮质细胞)也只响应特定方向的光,但是不再对区域敏感,这些光可以在屏幕上移动而不会导致失活。这可以解释为一组简单的皮层细胞在复杂细胞上汇聚。
由这些现象得到的结论有
- 每个处理步骤中,许多中间神经元的输入集中到一个输出上
- 因此,每一步中,有一些信息被选择性销毁了 (例如对于一个简单的皮层细胞,当某些LGN细胞在上面汇聚时它才会激活)
- 通过这种方式,大脑每个级别都会充当过滤设备,这种机制能够区分某些非常复杂的特征
- 哺乳动物的大脑不响应特定电路的特定脉冲,而是响应许多脉冲时空上的汇聚电路
由于这项发现,Hubel和Wiesel共享了1981年的诺贝尔奖。这项发现不仅在生物学上留下浓墨重彩的一笔,而且对20年后人工智能的发展埋下了伏笔。
熟悉CNN的同学可能已经察觉到这项发现和人工神经网络中很多概念都有呼应。
最直接的就是如下图的多层级结构,这项研究发现几层不同的细胞,最早的视网膜和LGN用于接受视觉信息并做初步处理响应光点,然后简单细胞开始响应线条,再之后复杂细胞和超复杂细胞做进一步处理。
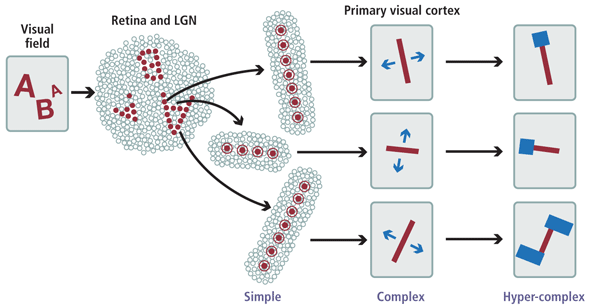
另一个就是过滤(filtering)的概念,我们不同细胞只对特定的输入感兴趣,而会过滤掉其他的信息。例如有的细胞只响应45°的线条,有的只响应某些颜色

此外还有本地连接,即每个神经元不会对整个图像做出响应,它只会对其本地附近的区域感兴趣。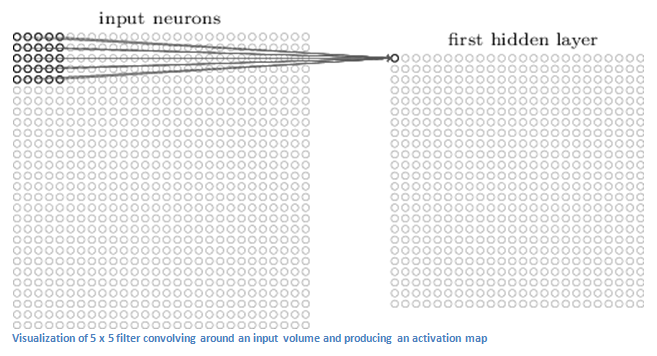
最后但是同样重要的概念就是平移不变性(这里也有把不变性说做是等变性的,这两种说法从不同角度来看是可以等价的,这里不过过多讨论,统一称作不变性,感兴趣的可以看这里的讨论),之前的实验表明了,即使我们将屏幕中的光条平移,猫的复杂视觉神经元依然能够被激活。 之后的研究发现,这种不变性不仅体现在平移不变上,同时也可以处理图像的翻转裁剪放缩等等。再后来的发现表明,优先复杂细胞能够保持的不变性非常的广,一个针对人类病患的实验找出病人脑中对著名演员Halle Berry响应的那部分神经元(我也不知道他们怎么能找到的),接着实验发现无论是长发还是短发,乃至穿上了猫女服装遮掩,甚至含有halle berry名字的文本都能激活该神经元。 这种不变性被认为是启发了神经网络中池化单元的设计。

虽然我们在生物上得到了很多启发,但是我们对人类大脑的工作机理的了解仍然只是皮毛,由此也给仿生的CNN留下许多疑惑。例如:
- 我们不了解大脑是如何训练这个网络的
- 之前所说的简单细胞和复杂细胞以目前生物技术来看没有生理上的不同,那么它又是通过何种方式用怎样的参数使得同样的结构能够发挥不同作用呢
- 我们观测到的视觉系统往往是不独立的,人类的视觉系统会集成许多其他感觉,例如听觉,心情等等。 而目前的CNN往往是负责纯粹一种感知。
- 现在简单细胞的线性处理已经比较明了了,但是复杂细胞如何达到非线性的呢,这一点还不得而知,这也为人工神经网络中激活函数的研究留下空间。
总之,这么来看,CNN中大部分重要的思想都在生物中有所体现,下面如何用在计算机中实现这种网络呢,就到了计算机科学大放异彩的时候了。
2000年以前
Neocognitron 1980
在Hubel和Wiesel因他们的卓越贡献获得诺贝尔奖的前一年,日本科学家福岛邦彦提出了neocognitron,其目标是构建一个能够像人脑一样实现模式识别的网络结构从而帮助我们理解大脑的运作。在这篇工作中,他创造性的从人类视觉系统引入了许多新的思想到人工神经网络,被许多人认为是CNN的雏形。Neocognitron是他之前工作Congnitron的改进,这里新的网络结构能够满足平移不变性。
我们先来看他的结构,这里,仿照生物神经网络,他设计了两种不同的cell,一种是simple cell,一种是Complex cell。对于输入多个区域,若干个Cell汇聚在一起各自处理一部分形成一个plane,而一层网络又由多个plane组成。
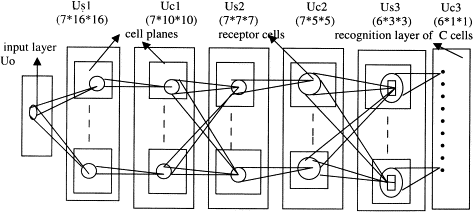
注意到这里示意图中有两点:
- 对于S-cell来说它只接受自己这个plane中上一层对应plane的结果作为输入,而对于C-cell来说,它会接受上层网络中多个plane的输出。
- 随着网络层数的加深,每个cell的感受野越来越大,也由此每个plane包含的cell个数也越来愈少。
该结构与生物结构一一对应起来就是:先是简单细胞,然后复杂细胞,低阶超复杂细胞,高阶超复杂细胞,最后到祖母细胞。
注意一下这里简单细胞的突触是不可修改的(也就是设定初始值后就不再变化了)
为了简洁起见,另外图中画出的cell都是激活的cell,但是每个layer中也有被抑制的S/Ccell。
下面我们来看一下细节部分: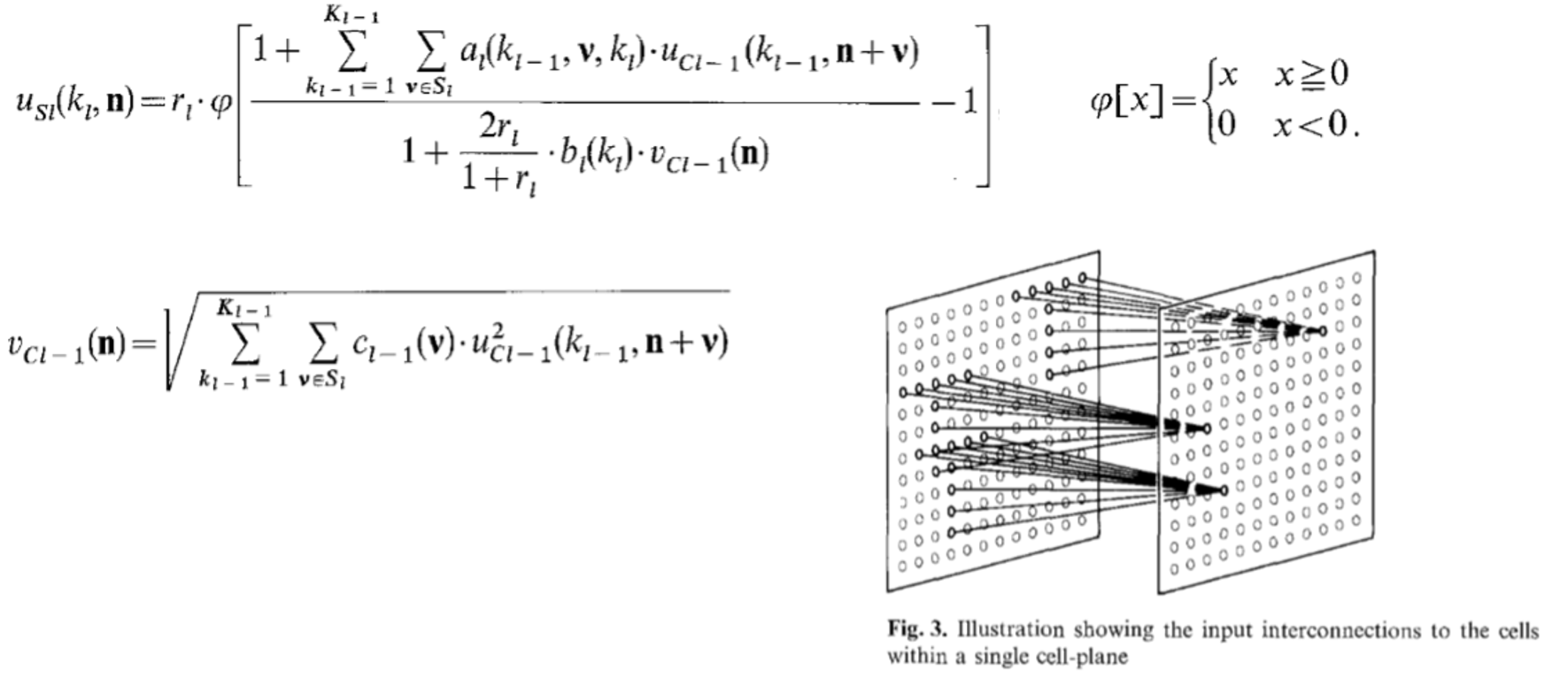
这里update S-cell的部分,l是层数,而k是plane编号。这里r是表示这一层的激活的效率,而$\varphi$ 起到的作用类似于线性整流器。
仔细来看激活函数内的部分:分子上是可以看作是对前一层C-cell输出的加权求和,这个操作可以被看作是一个averaging pooling的池化。a表示兴奋突触的效率,外层循环是针对plane的,内层循环则是针对cell的感受野的,这里n可以视为position,v则可以看作是偏移。每个plane中cell的感受野形状相同,如图这层感受野就是一个T形的区域,那么所有cell的是使用的一个相同的感受野。分母上是上一层被抑制突触的部分,b表示抑制效率,v是被抑制的C-cell,其计算公式可以看作是RMS type的映射。
我们可以看到,这里每个S-cell的特征提取在形式上都是并行的,只是其处理的感受野的位置不同,因此,如果能够激活某个S-cell的模式位置进行了变动,那么被激活的S-Cell的位置也会做相应的变动。
C-Cell的处理类似S-Cell,但是形式上更简单些,每个C-cell只接受上一层其对应的plane的信息。这里就不再多说了。
总结起来Neocoginitro有哪些贡献呢?
- 将脑神经科学的结构在做了计算机模拟
- 提出了现在CNN常用的step-by-step的filter
- 使用ReLU来给网络提供非线性
- 采用平均池化来做downsampling
- 保证了网络的平移不变性
- 实现了稀疏交互
这么一看的话,基本上大部分现代CNN的结构在这个模型上都已经得到了体现。卷积运算的三个重要思想:稀疏交互,参数共享和等变表示也只有参数共享没有考虑到了。
但是这个模型虽然做的非常漂亮,但是其最大的局限在于它是使用基于WTA(Winner Take All)的无监督学习,因此这个很fancy的模型一直很欠缺实用性。
BP for CNN 1990
接下来十年间CNN方面都没有出现大的突破,直到十年后大概1989到1990左右,LeCun将反向传播应用到了类似Neocoginitro的网络上来做有监督学习。这下子就像是解开了五指山上的封条,CNN开始逐渐走向各个应用领域。
LeCun在这篇论文中延续了他在巴黎六大博士论文的工作,将BP延展开来。我们先来看这个网络里面定义的卷积操作,他吸取了Neocognitro的稀疏交互的优点,但他和福岛邦彦的网络最大不同在于,我们在生成每个feature map时,在所有的感受野都只用单个神经元。那么整个卷积操作就等价于用一个小尺寸的卷积核去扫描这个输入然后接一个squashing function。这个特性也就是权值共享,这个操作减少了自由变量的数量,也就减少了过拟合的风险,提高了泛化能力。参数的减少同时也加速了训练过程。
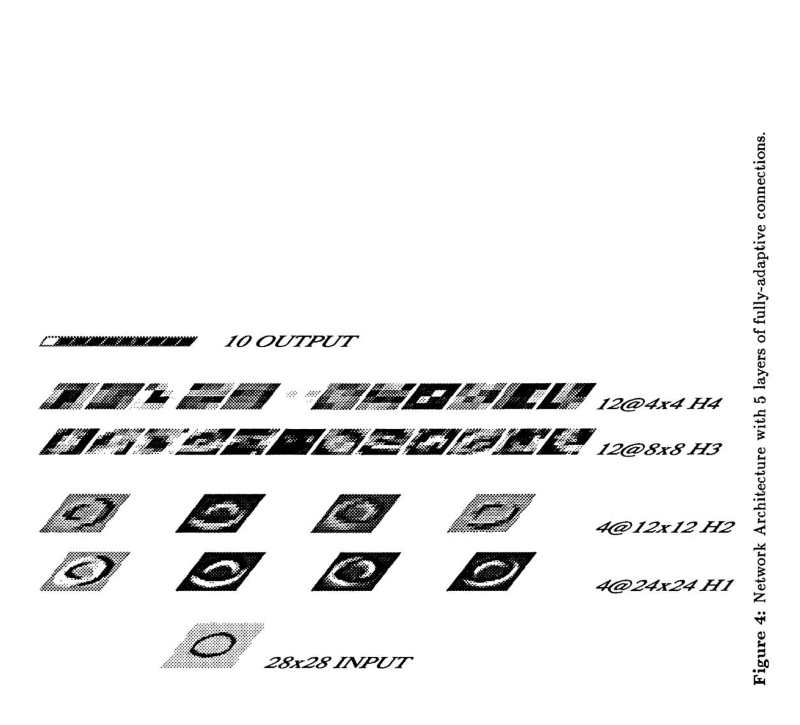
接下来来看下这个网络的结构,其实熟悉现代CNN架构的就已经很明白了。这里共有四层隐层和一层输出,其中H1和H3都是卷积层,而H2和H4都是downsampling层。其实网络架构并不是这篇论文的两点,虽然这篇文章提出了权值共享这一重要的思想,但是最重要的是它简化了卷积操作,便于将反向传播应用到CNN上,并且利用它解决了一个实际世界中的问题。
Cresceptron 1992
接着,在1992年,美籍华裔科学家翁巨杨发表了他的Cresceptron,虽然从结构上来看他的模型没有非常出彩之处,而且由于当时想模拟人脑的这种朴素思想,没有延续使用BP的监督学习而是用了一种非监督学习(也许在今天模拟人脑这种想法和强化学习的路子更近一些,人类在辨识物体时既不能看作是监督式学习,但也不能看作是完全的无监督)。但是这篇论文中的两个trick却被广泛应用至今。
其中第一个是数据增强(Data Augmentation),我们将训练的输入进行平移,旋转,缩放等变换操作然后加入到训练集中,一方面这可以扩充训练集,另一方面也提高了算法的鲁棒性,减少了过拟合的风险。
第二个技巧是最大池化的提出,改变了千篇一律的用平均池化做downsampling的状况。
有趣的是,今天看来,这篇论文中这两个较大的贡献在原文中却并没有作为亮点来讲,论文中着力强调的点反而时至今日无人问津。
LeNet-5 1998

时间来到世纪之交的1998年,LeCun同志在这一年用一篇长达46页的巨作提出了LeNet-5,虽然这篇工作中用了较多的篇幅去介绍整个自动识别系统,而不是针对单个被切割好的字母图片。但是我们这边还是只关注它的网络方面。
简单看一下LeNet-5的结构,和我们现在经常看到的CNN已经别无二致了。相比之前的工作,这里网络层数加深到了7层。其中两层卷积两层池化。
我们注意到这里从S2到C3的feature map数从6个增长到16个,显然两层之间并非一一映射,那么这里的映射关系是怎样的呢? 我们看左下这张图,反应了C3中不同的feature map的输入。这里也没有使用全连接,而是不同的feature map会有3~5个不同个数的不同范围的S2的输出作为其输入。 这里有两个好处,其一就是不用全连接减少了连接的个数。但是更重要的是这种安排打破了不同feature map间的对称性,回想集成学习里我们需要尽可能多样的基学习器,这里也是同样的思想,保持各个feature map和而不同有利于其表征的鲁棒性。
LeNet-5还有一些有趣的细节,一个是使用了tanh作为激活函数,这里作者表示对称的激活函数能够更快收敛,我理解这里不用ReLU的原因在于98年的时候,网络的深度还不太深,因此梯度消失不是一个太大的问题,而相比之下加速收敛的性质更加重要。
此外论文在附录对比了随机梯度下降和批梯度下降 ,指出随机梯度下降以及mini-bathSGD能够极大加快拟合速度,并且最终效果很好。但是他也指出SGD在理论上还没有可靠的理解。
另一个改变是,在输出层,LeCun用RBF layer取代了原来惯用的全连接层:
这里的w是参数,从形式上看,这里的输出像是输入和参数差值的一个惩罚项。从概率论的角度来看,RBF的输出可以被视作一个未被正则化的负的log似然的高斯分布。 这里使用RBF的好处在于,我们可以手工设定RBF的参数,比如这边F6层的输出是84位,我们将其组成一个7x12的位图,并提供这个如下图的打印体位图作为参照来设定RBF的参数。这个操作在判断0~9的数字时没有很大的效果提升,但是当候选项从数字变成全部的ASCII字母时,这种操作相较之前的方法在容易引起歧义的图像上(例如数字0和字母O)表现有了很大的提升。

这篇论文中,其baseline涵盖了几乎所有主流的机器学习方法,LeNet也技压群雄。本来以为这是神经网络崛起的号角,但是由于计算能力限制和SVM的大放异彩,神经网络在21世纪初迷失了近10年。
2000年之后
GPU-CNN 2006
进入到新世纪,第一个突破并不是在算法上的,而是工程上。2006年,研究人员成功利用GPU加速了CNN,相比CPU实现快了4倍。虽然这里没有算法的提升,但是其意义可能比一般的算法提升更大。
AlexNet 2012
直到2012年,这一年AlexNet的出现可以说是标志着神经网络的复苏和深度学习的崛起。在imageNet2012的图片分类任务上,AlexNet以15.3%的错误率登顶,而且以高出第二名十几个百分点的差距吊打所有其他参与者。而且从此,ILSVRC这个竞赛称为深度学习的风向标,每年的优秀队伍的解法都会得到极大关注。从2015年开始,以商汤科技,旷视科技,海康威视,公安部三所等机构为代表,中国队伍也在该项竞赛中争金夺银。由于到了2016年,state-of-the-art已经达到了2.99%,远远超过人类5.1%的水平,因此,2017年被定做是最后一届ImageNet的图像分类竞赛。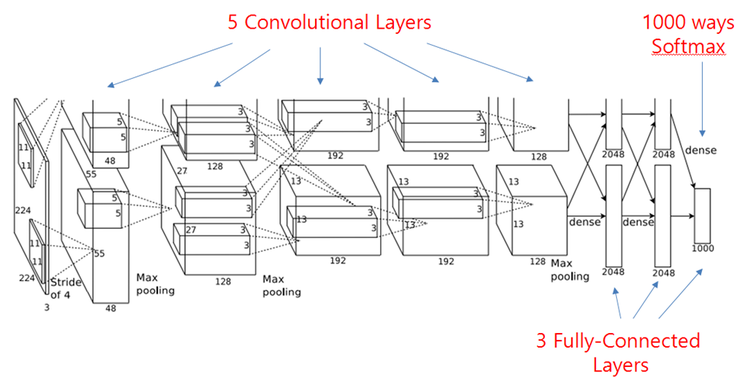
回到AlexNet,这里又用了什么新的CNN技术呢。其实总的来看,卷积/池化操作没有太大变化,不过层数有所加深。
整个网络主要的点有:
- 使用了ReLU作为激活函数,其实我们之前提到这在1980年的时候就已经被应用过了,不过十几年前LeNet又因为种种原因改为tanh。
- 使用了数据增强,这点在92年的Cresceptron被引入。
- 使用了mini-batch SGD,这是98年LeNet的做法。
- 在GPU上训练,这得益于06年CNN在GPU上的实现。
- 实现了Dropout层来避免过拟合。
大家可以发现除了最后一点Dropout之外,其他的亮点都是之前其他人工作的拼接。这点倒是启发了我,其实老论文有的时候比新出炉的论文更值得读,一来随着热度提升,各个会议的注水量稳步攀升,新出论文的质量相比经时间考验的老论文而言更低,研究research,拆开来就是re-search,不断搜索之前的想法,也许能得到新的思路。
总之,AlexNet成功的打响了第一枪,这之后新的 CNN层出不穷,甚至你出去吃个午饭的功夫世界上就有一个新的CNN被提出。因此下面我们就挑选一个一个具有代表性的来说一下。
ResNet 2015
这篇论文就是15年底何凯明大神提出的ResNet,要说它的最大特点的话,就是很深。他也是第一个在ImageNet图片分类上表现超过人类水准的算法。
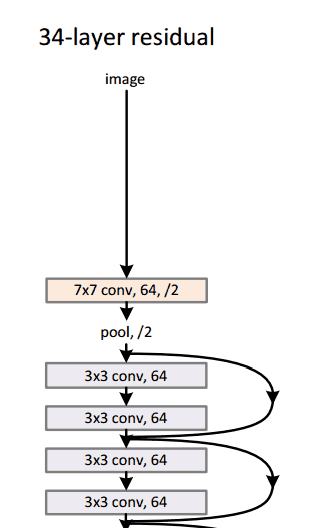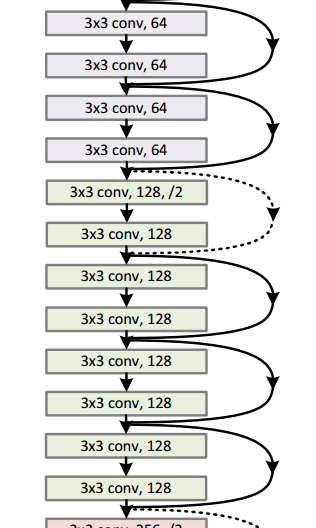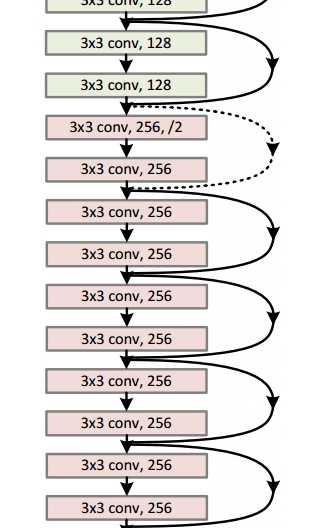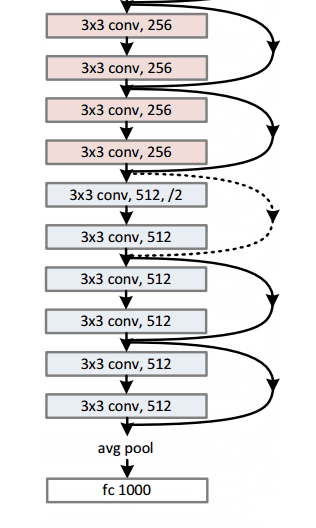
其实我们之前提到了,ImageNet竞赛上面,使用的模型的层数逐年加深,但是人们发现,越深的网络越难以训练,往往会会遇到梯度爆炸,梯度消失,梯度弥散等问题而导致网络退化。那么ResNet是如何解决这个问题的呢?
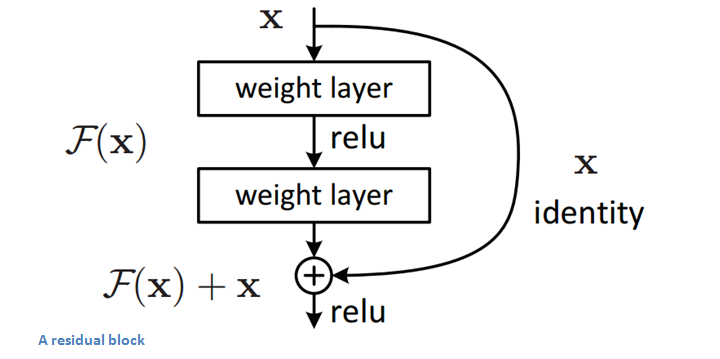
下面我们来看这个网络中最重要的组成部分,也就是残差块。纵向来看,这个模块有三层,是两层卷积(也可以是全连接)包含了一层激活,另外,还有一条线将输入直接短接到下面的加法上去。也就是微观上来看,我们这个小模块学习到的是原始输入和期望输出的差值。通常来说我们的不同层的feature map往往是在不同的空间中的,这里,加上去的这个x给输出提供一个reference,使得输入输出落在一个空间中。这样能够保证随着深度的提高,其feature map不会有太难以掌控的变化,从而解决了网络退化的问题。其实在此之前,已经有相关文章研究了短路的问题,但是通常都是用一个依赖于其他参数的gate去控制这种短接,这里将大门常年打开,最终避免了网络退化。
回顾和展望

那么回顾一下这些年的CNN的发展,它能够取得这么耀眼的成绩主要得益于以下几点:
- 首先是卷积和池化带来的 转换不变性
- 第二个就是尺度分离,这里是由这种多层的结构带来的,这个思想可追溯到1968年的Simple Cell和Complex Cell
- 然后就是利用了空间的本地性
- 接下来就是由稀疏连接,权值共享带来的参数个数的下降而提升了计算效率。
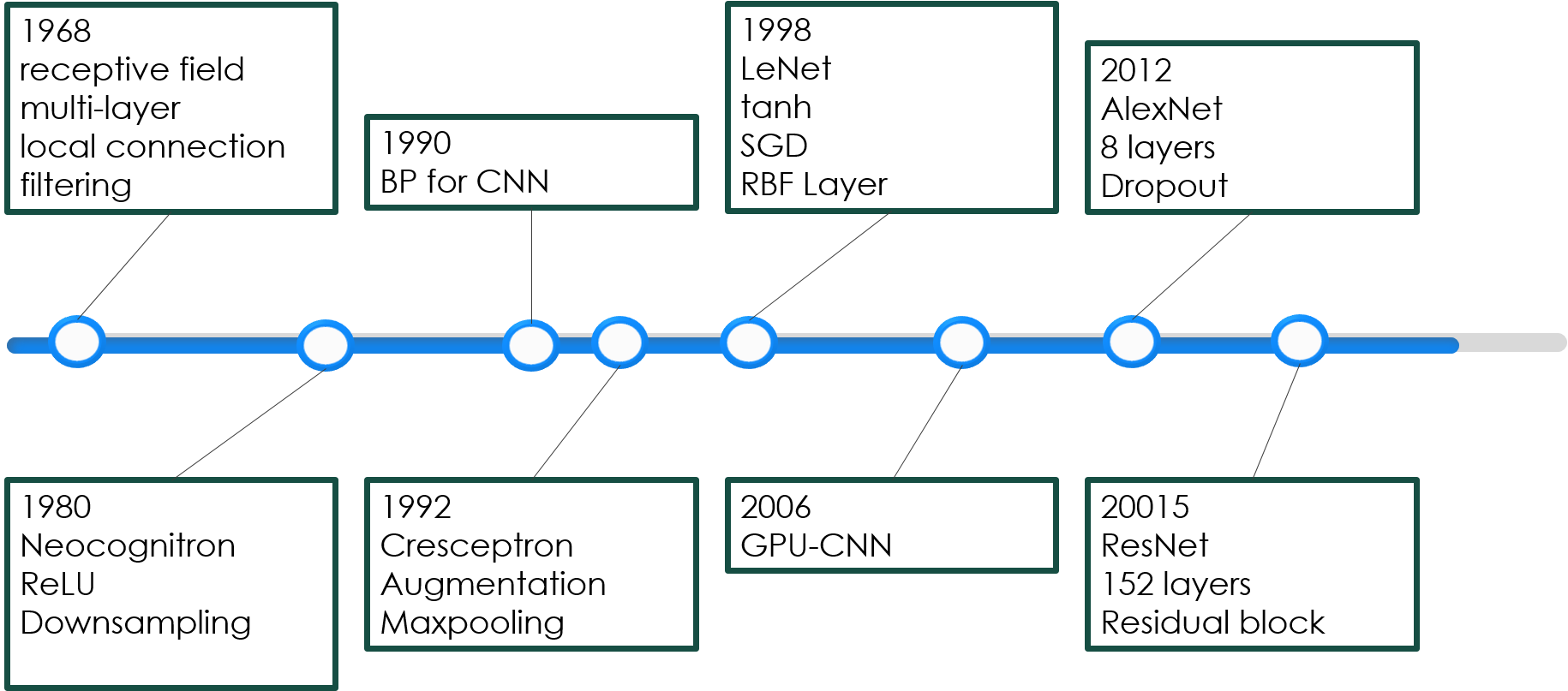
回顾一下CNN发展史,可以发现,大部分问题其实都是在2000年前搞定的。
我们不妨来对比一下2012年的AlexNet和14年前的LeNet-5. 我们的输入的数据量提高了$10^3$,计算速度提高了20倍左右,而算法似乎只是在原来的基础上加深了一些,另外加了一些精细化的正则化或是改了下激活函数。所以其实新世纪中深度学习的成就在更多程度上是由我们数据量增加,计算能力增加带来的,而非算法的改进。很多人也对现在这种军备竞赛式的拼谁家GPU多的发展模式产生了质疑。
The pooling operation used in convolutional neural networks is a big mistake and the fact that it works so well is a disaster.
I am deeply suspicious of back-propagation, my view is throw it all away and start again.
—Geoff. Hinton
Hinton在14年的时候就说过,CNN的池化操作是一个大错,而由此带来的效果则是一场灾难。他对自己搞出来的反向传播深表怀疑,觉得我们应该抛下这些重起炉灶。
当然Hinton这种大牛也没啥科研压力了自然有底气说这些,不过马云不也说“我对钱没有兴趣”,“我这辈子最后悔的就是创建阿里巴巴”嘛。在2014年Hinton给出了一个名为“What is wrong with CNN”的演讲,提出了四点质疑。其中有的点现在已经部分解决,有的观点时至今日仍发人深省。有兴趣的同学可以去youtube看一下这个演讲。

这些质疑都预示着,CNN的进一步发展不能再仅仅依靠简单的改改模型了。在前沿的研究中,其中很有前景的是这三个方向。
分别是,基于球体做CNN,在流形上做CNN和在图上做CNN。这三者都可以看作是将传统CNN从欧几里得空间向外延展到非欧空间,分别到黎曼空间,流形空间和图上。
大家看近几年ICLR,ICML以及NIPS上比较有影响力的文章,有许多都是在这三个方向做文章。
参考文献
- Alex Krizhevsky; Ilya Sutskever; Geoffrey E. Hinton: ImageNet Classification with Deep Convolutional Neural Networks.
- Deep Learning in Neural Networks - An Overview.
- Deep Residual Learning for Image Recognition.
Fukushima, Kunihiko (1980): Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. In Biol. Cybernetics 36 (4), pp. 193–202. DOI: 10.1007/BF00344251. - Going Deeper with Convolutions.
- Yann LeCun; Bernhard E. Boser; John S. Denker; Donnie Henderson; R. E. Howard; Wayne E. Hubbard; Lawrence D. Jackel: Handwritten Digit Recognition with a Back-Propagation Network.
 wechat
wechat alipay
alipay






