Go Smaller:预训练模型蒸馏之道
【注意】:此篇仅为个人笔记备忘之用,可能存在缺乏必要信息、逻辑不连贯、缺少引用等问题,仅供参考。
基本蒸馏
Why:用学生模型去学习教师模型的泛化能力,而不是仅仅拟合训练数据。
How:学生模型的loss中同时加入和教师模型的拟合项。
其中前一项拟合hard label,后一项拟合soft label,即教师模型的输出概率。$\alpha$为蒸馏loss权重。为了控制教师输出概率的平滑成都,通常教师模型的softmax需要加一个temperature (T) 超参数。
不难看出,$T=0$时,就是一个Kronecker分布(one-hot),$T=+\infty$时,就是一个均匀分布。
蒸馏BERT
由于BERT很大,所以实际应用时需要瘦身,也出现了不少针对BERT的蒸馏技术。
Distilled BiLSTM
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks: https://arxiv.org/abs/1903.12136 (2019)
该方法主要是将BERT蒸馏到单层的BiLSTM中去,教师模型就是BERT-large,学生模型采用BiLSTM-ReLU。
同时作者也改了蒸馏的目标函数,soft label项那里由交叉熵改为logits之间的MSE。
BERT-PKD
Patient Knowledge Distillation for BERT Model Compression: https://arxiv.org/abs/1908.09355 (EMNLP 2019)
该文章提出了Patient Knowledge Distillation,从教师模型中间层来提取知识,避免在蒸馏最后一层时过拟合。
这样,在loss中,还要加入中间结果的PT loss。
】、、we’e BERT-PKD
BERT-PKD
DistillBERT
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter: https://arxiv.org/abs/1910.01108 (NIPS 2019)
之前的大多数方法都是在finetune好的BERT上蒸馏,HuggingFace给出了一种方法,在预训练阶段就开始蒸馏。
教师模型使用BERT-base,学生模型则使用一个6层transformer。
学生模型去除了token-type embedding和pooler,而其他部分的层数只有原来的一半。
作者在博客中给出了几个关于该工作的疑问。
- 为啥不减少hidden size? 现代模型中,大部分的操作都是集中优化最后一层的tensor。而且实验表明,推理速度和层数更相关。
- 一些工作使用L2 distance来作为蒸馏loss,这里为啥不用呢? 我们的实验表明,cross-entropy loss的效果明显的好很多
实际工程中还有几个细节:
- 训练一个子网络,初始化很重要,这里用的是教师网络中的部分层参数来初始化。
- 训练的时候要增大batch size (very large batch),使用dynamic masking以及remove the next sentence prediction objective
TinyBert
TinyBERT: Distilling BERT for Natural Language Understanding: https://arxiv.org/abs/1909.10351 (EMBLP2019)
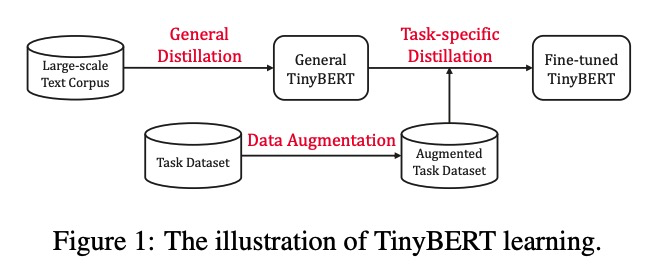
TinyBert 提出了一个two-stage learning框架,分别在预训练和精调阶段来蒸馏模型参数量减少7.5倍,效果可以达到教师模型的96.8%。
蒸馏loss
具体来说,若teacher model中有M层,student model中有N层,那么从teacher model的M层中选出N层来建立mapping,对S/T model中对应的层算一个损失函数。
Transrformer-layer中的hidden layer两两做MSE,Embedding-layer中的embedding两两做MSE,以及Prediction-layer中的logits两两做Cross-entropy。
此外,前人的研究指出,注意力矩阵中蕴含大量语义知识,因此提出来讲注意力矩阵也做蒸馏,采用教师-学生注意力矩阵logits的MSE作为损失函数。
Two-stage蒸馏
General Distillation是第一次蒸馏,这一遍蒸馏的时候不用加入prediction-layer的loss,目的是让general TinyBert主要学习BERT的中间层。
Task-specific Distillation是第二遍蒸馏。有研究指出预训练模型在domain-specific task具有over-parameterization的问题,因此,需要用fine-tune的模型来给student model做第二次蒸馏。这里作者还给出了一种数据增强方法,主要是用word-level replacement完成。
MobileBert
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices: https://arxiv.org/abs/2004.02984
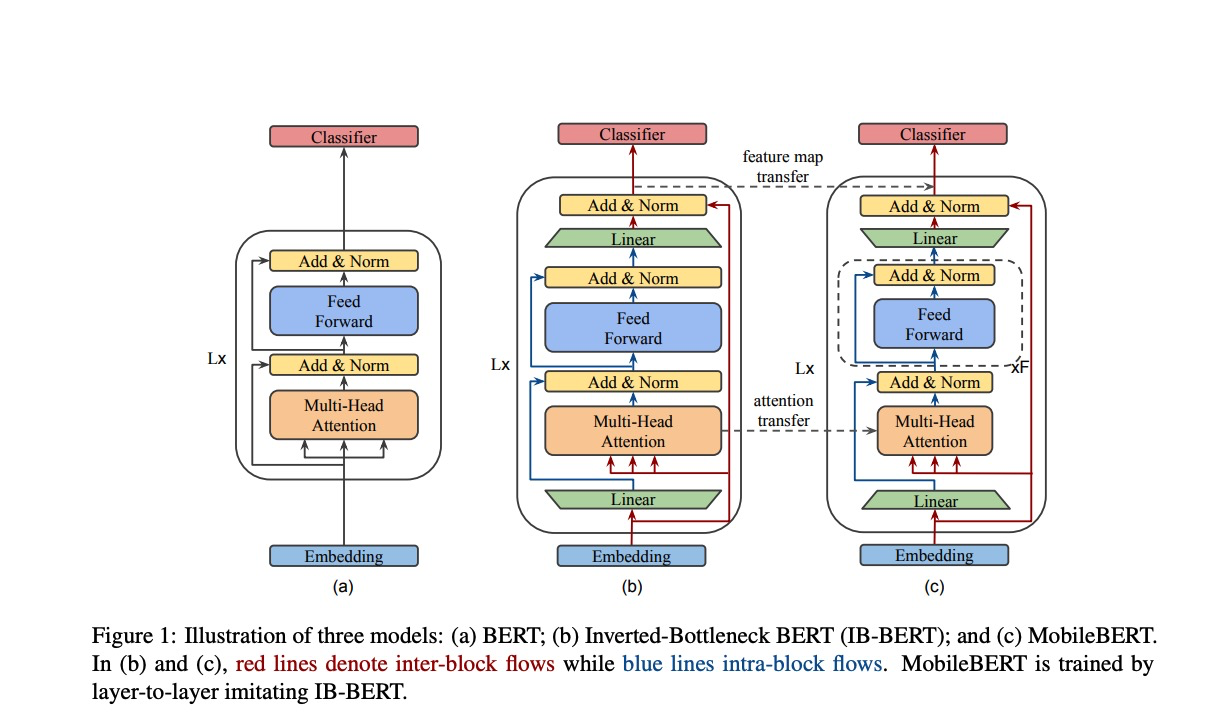
MobileBERT是CMU和Google提出的一个模型,相比之前的模型,它并没有想降低层数,而是致力于减少每层的宽度。
如下图所示,中间的模型是一个精心设计的Transformer teacher model (Inverted-Bottleneck BERT) ,右侧则是student model。
Bottleneck 和 Inverted-Bottleneck
student model里每个block中的hidden dimension为128,但是每个block前后各加了一个512->128/128->512的线性变换来将维度调整回512。 由于这样又深又瘦的模型很难训练,因此需要先训练一个同feature map size的teacher model。而作者发现,在student model使用bottleneck block的同时,如果给teacher model做inverted-bottleneck 增强,即在block前后各加一个线性层,使block内dimension增大,可以保证student model效率的同时尽可能保留大模型的性能。
MHA和FFN的平衡
作者提出,bottleneck的加入破坏了传统BERT中多头注意力机制(MHA)和FFN(Feed Forward Network)的平衡,即参数量比例为1:2。为了解决这个问题,MobileBERT中的block叠加了多层的FFN。
效率优化
为了提高训练、推理速度,作者还做了一些trick,例如用pointwise product替代LayerNorm:
其中$\circ$为Hadamard product (pointwise product)。这里其实没太看懂,确实速度快了,但是LN的效果还有么。
此外,用relu替代gelu作为激活函数也可以加速。
目标函数
蒸馏时的目标函数主要有两个模型间feature map的MSE误差,attention矩阵的KL散度,以及pretraining的distillation loss(MLM,NSP,KD)。
同时作者还研究了三种不同的蒸馏策略:直接蒸馏所有层、先蒸馏中间层再蒸馏最后一层、逐层蒸馏。 逐层蒸馏好一点,但是好的有限,性价比很低。
MINILM
MINILM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers: https://arxiv.org/abs/2002.10957
MINILM是微软做的模型压缩工作,主要是提出了其实大模型最重要的就是最后一层,其他的都是其次。那我使劲蒸馏最后一层,把更多的信息保留到学生模型中去就得了。围绕这方面做了很多工作。此外,作者还提了一种助教机制可以帮助蒸馏。
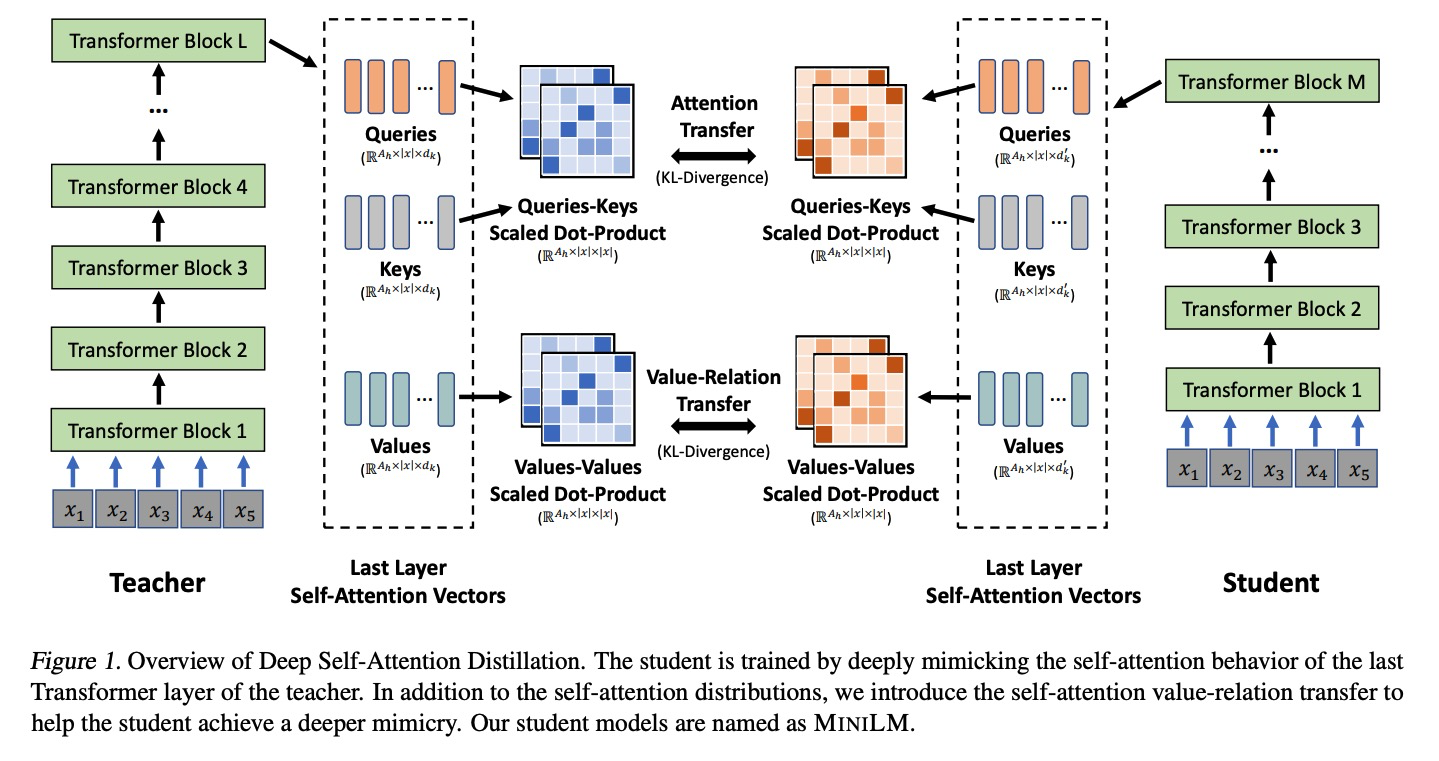
这篇工作的蒸馏主要有以下几个方面:
- Self-attention Distribution: 将Teacher、Student Model的最后一层Transformer注意力矩阵的分布的KL散度加入loss (上图中间上部)。
- 除了attention distribution,作者还提出要蒸馏TS之中的value-relation(上图中间下部)。
这里考虑两点:
1. 加入Lvr可以帮助学生模型深度模仿教师模型的self-atention behavior。
2. 使用scaled dot-product可以使不同的hidden dimension化到同一维度。
- 助教机制,简单的说就是在教师模型(大模型)和学生模型(小模型)中间再加一个助教模型(中模型),先从大模型蒸馏到中模型,再从中模型蒸馏到小模型。
这篇文章最大的贡献在于只用蒸馏最后一层就能取得很好的性能,相比之前的模型方便很多。
 wechat
wechat alipay
alipay






